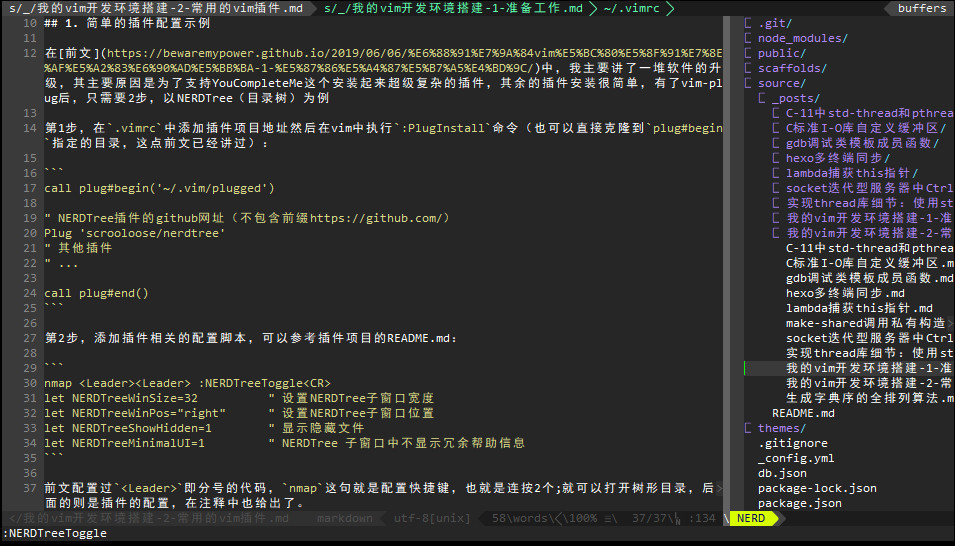
nmap<Leader><Leader> :NERDTreeToggle<CR> let NERDTreeWinSize=32" 设置NERDTree子窗口宽度 let NERDTreeWinPos="right"" 设置NERDTree子窗口位置 let NERDTreeShowHidden=1" 显示隐藏文件 let NERDTreeMinimalUI=1" NERDTree 子窗口中不显示冗余帮助信息
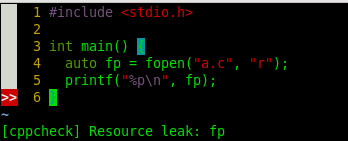
"" ale let g:ale_linters = { \'c': ['gcc', 'cppcheck'], \'cpp': ['g++', 'cppcheck'], \ } let g:ale_c_gcc_options = '-Wall -O2 -std=c99 \ -I . \ -I /usr/include' let g:ale_cpp_gcc_options = '-Wall -O2 -std=c++11 \ -I . \ -I /usr/include \ -I $HOME/local/gcc-5.4.0/include/c++/5.4.0' let g:ale_c_cppcheck_options = '' let g:ale_cpp_cppcheck_options = ''
let g:ale_linters_explicit = 1" 只显示运行ale_linters的文件 let g:ale_completion_delay = 500 let g:ale_echo_delay = 20 let g:ale_lint_delay = 500 let g:ale_echo_msg_format = '[%linter%] %code: %%s' let g:ale_lint_on_text_changed = 'normal' " 防止YCM不停补全 let g:ale_lint_on_insert_leave = 1
" Do not use <tab> if you use YouCompleteMe letg:UltiSnipsExpandTrigger="<tab>" letg:UltiSnipsJumpForwardTrigger="<c-b>" letg:UltiSnipsJumpBackwardTrigger="<c-z>"
" If you want :UltiSnipsEdit to split your window. letg:UltiSnipsEditSplit="vertical"
wget http://releases.llvm.org/8.0.0/llvm-8.0.0.src.tar.xz tar xvf llvm-8.0.0.src.tar.xz mv llvm-8.0.0.src llvm cd llvm/tools wget http://releases.llvm.org/8.0.0/cfe-8.0.0.src.tar.xz tar xvf cfe-8.0.0.src.tar.xz mv cfe-8.0.0.src clang cd clang/tools wget http://releases.llvm.org/8.0.0/clang-tools-extra-8.0.0.src.tar.xz tar xvf clang-tools-extra-8.0.0.src.tar.xz mv clang-tools-extra-8.0.0.src extra cd ../../../projects/ wget http://releases.llvm.org/8.0.0/compiler-rt-8.0.0.src.tar.xz tar xvf compiler-rt-8.0.0.src.tar.xz mv compiler-rt-8.0.0.src compiler-rt
" 定义<leader>为分号,此行代码必须在插件配置代码之前 let mapleader=";" " 在处理未保存或只读文件的时候,弹出确认 set confirm " 自适应不同语言的智能缩进 filetype indent on " 设置编辑时制表符占用空格数 settabstop=4 " 设置格式化时制表符占用空格数 set shiftwidth=4 " 将制表符扩展为空格 set expandtab " 让 vim 把连续数量的空格视为一个制表符 "setsofttabstop=4 " 显示行号 set number "搜索忽略大小写 "set ignorecase "搜索逐字符高亮 set hlsearch set incsearch " 使回格键(backspace)正常处理indent, eol, start等 set backspace=2 " 允许backspace和光标键跨越行边界 set whichwrap+=<,>,h,l " 在被分割的窗口间显示空白,便于阅读 set fillchars=vert:\ ,stl:\ ,stlnc:\ " 高亮显示匹配的括号 set showmatch " 匹配括号高亮的时间(单位是十分之一秒) set matchtime=1 " 光标移动到buffer的顶部和底部时保持3行距离 setscrolloff=3
staticvolatilebool run = false; ::signal(SIGINT, [](int) { run = false; }); run = true; while (run) { // ... int ret = some_system_call(); // 代替某些自动重启的系统调用 if (ret == -1) { if (errno == EINTR) break; // else ... } }
在C++11中,单靠thread是无法取得线程函数的返回值的,必须得借助async等异步设施,*Effective Modern C++*也推崇使用基于任务的并发编程而非基于线程。当然这个是后话了, 现在,我就是想直接取得线程函数的返回值,又不继续写pthread那套麻烦的线程函数,那么直接在std::thread的线程函数中调用pthread API?于是有了下面这段代码。
intmain(){ // NOTE: make sure cast between long and void* is safe. std::thread t([] { pthread_exit(reinterpret_cast<void*>(1)); }); void* ret; pthread_join(t.native_handle(), &ret); printf("thread exit with %ld\n", reinterpret_cast<long>(ret)); return0; }
编译运行,结果如下
1 2 3 4
# g++ -std=c++11 test.cc -pthread && ./a.out thread exit with 1 terminate called without an active exception Aborted
嗯?是不是还要调用t.join()?于是我加上了t.join()。
1 2 3 4
thread exit with 1 terminate called after throwing an instance of 'std::system_error' what(): No such process Aborted
PS: 为何析构函数禁止抛出异常,以及noexcept的概念,分别参考*Effective C++和Effective Modern C++*的相关条款。 哦对了,刚才分析的前提是,__g前缀可以被替换成p,为何可以呢?原因是gcc实际上也是跨平台的,因此会定义一组别名来屏蔽系统API的差异。由于Linux是遵守POSIX接口的,所以这组定义在gcc项目的libgcc/gthr-posix.h中,在该头文件中可以看到下列定义
1 2 3 4
typedef pthread_t __gthread_t; /* Typically, __gthrw_foo is a weak reference to symbol foo. */ #define __gthrw(name)__gthrw2(__gthrw_ ## name,name,name) __gthrw(pthread_join)
structFoo { voidf(){ std::unique_ptr<int> p; auto f = [=] { cout << p.get() << endl; }; f(); } };
编译出错(嗯,其实在编译前,我的vim插件ale已经提示了错误)
1
use of deleted function 'std::unique_ptr<_Tp, _Dp>::unique_ptr(conststd::unique_ptr<_Tp, _Dp>&)[with_Tp = int; _Dp = std::default_delete<int>]
那么,也就是说,类成员函数中的lambda表达式并不是像捕获局部变量一样”捕获”类成员变量,而是通过某些其他途径得以访问类成员变量。 参阅*Effective Modern C++*后面的部分(嗯,我从前往后抽空看的,目前还没看完),恍然大悟。 在条款31:避免默认捕获模式中,书上举出了一个类似例子,并给出了说明
int () => int (*)() int (&)() => int (*)() int [10] => int* int (&) [10] => int* intconst => int intconst& => int intconst* => intconst* int* const => int*
void* threadFunc(void* arg){ auto input = static_cast<input_type*>(arg); // do sth... and generate an exit_code returnreinterpret_cast<void*>(exit_code); }
int main() { int i = 0; int& ri = i; auto p = makeDataTuple(f, std::ref(ri)); get<0>(p->t_)(get<1>(p->t_)); cout << i << endl; //1 //delete p and exit. }
(gdb) b BlobPtr<int>::operator++ Breakpoint 1at0x402099: BlobPtr<int>::operator++. (2 locations) (gdb) i b Num Type Disp Enb Address What 1breakpoint keep y <MULTIPLE> 1.1 y 0x0000000000402099 in BlobPtr<int>::operator++() atBlob.h:137 1.2 y 0x000000000040217e in BlobPtr<int>::operator++(int) atBlob.h:151 (gdb) b BlobPtr<int>::operator++(int) Note:breakpoint 1 also set at pc 0x40217e. Breakpoint 2at0x40217e: file Blob.h, line 151. (gdb) i b Num Type Disp Enb Address What 1breakpoint keep y <MULTIPLE> 1.1 y 0x0000000000402099 in BlobPtr<int>::operator++() atBlob.h:137 1.2 y 0x000000000040217e in BlobPtr<int>::operator++(int) atBlob.h:151 2breakpoint keep y 0x000000000040217e in BlobPtr<int>::operator++(int) atBlob.h:151
# ldd a.out | grep libc libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f49ed348000) # /lib/x86_64-linux-gnu/libc.so.6 GNU C Library (Ubuntu GLIBC 2.23-0ubuntu9) stable release version 2.23, by Roland McGrath et al.
int _IO_vsnprintf (char *string, _IO_size_t maxlen, const char *format, _IO_va_list args) { // 该结构体包含2个字段 // _IO_strfile f; // 文件相关结构,暂不深入 // /* This is used for the characters which do not fit in the buffer // provided by the user. */ // 重点在这,定义了额外的缓冲区来保存用户缓冲区可能无法保存的字符 // 比如snprintf(buf, 2, "%d", 10000); // 用户缓冲区buf光2个字节无法保存"10000"这5个字符,多余的就存在overflow_buf中 // char overflow_buf[64]; _IO_strnfile sf; int ret; #ifdef _IO_MTSAFE_IO sf.f._sbf._f._lock = NULL; #endif
/* We need to handle the special case where MAXLEN is 0. Use the overflow buffer right from the start. */ // 通过snprintf(NULL, 0, format, ...)取得格式化后字符串实际大小就是在 // 这里实现的。利用了overflow缓冲区,并重置maxlen为其大小(64)。 // 因此string参数此时没有意义,可以随便设置,并不一定需要为NULL。 if (maxlen == 0) { string = sf.overflow_buf; maxlen = sizeof (sf.overflow_buf); }
hexo s s即server,默认在localhost:4000启动服务器,在浏览器中即可看到效果,可以通过-p选项指定端口。
hexo d d即deploy(部署),上传到服务器。一般会加上-g选项在本地生成静态文件。如果不上传服务器,可以直接hexo g生成静态文件。
hexo clean 删除本地md文件后如果不clean后重新生成,首页可能不会更新。
hexo new 新建博客,后接博客名,比如hexo new "test",此时hexo框架就会自动生成md文件。自动新建的md文件会生成一些模板信息,因此最好使用命令新建博客。生成之后,用vim等本地编辑器修改即可。 另外在_config.yml设置post_asset_folder为true,则hexo new会新建md文件的同名目录用来存放图片,并且作为图片的默认路径,也就是说如果待插入图片放在该目录下,路径直接写文件名即可。